

8 best Linux apps for system monitoring
Last Updated on May 26, 2024 by Jhonni Jets
System monitoring is an essential task for any Linux system administrator. It allows you to keep tabs on key system metrics like CPU and memory usage, disk space, network traffic, and more. By monitoring your servers, you can detect performance issues, security threats, and hardware failures before they impact your services or users. In this article, we will explore the 8 best Linux applications for system monitoring and discuss their key features and use cases.
As a Linux system administrator, monitoring your servers is crucial to ensure optimum performance and uptime. Having visibility into how your systems are operating gives you insight into bottlenecks, failures, and security risks. It allows you to be proactive in resolving issues before they impact users. While Linux offers many built-in monitoring tools like top, iostat, and ifconfig, dedicated monitoring applications provide more robust and user-friendly dashboards for a birds-eye view of all your servers.
Table of Content
In this article, we will cover 8 of the top open-source and commercial Linux system monitoring tools. For each tool, we will discuss its main features, installation process, and use cases. By the end, you should have a good understanding of the leading options for getting deep visibility into your Linux infrastructure from CPU utilization to disk I/O to network traffic and more.
Nagios
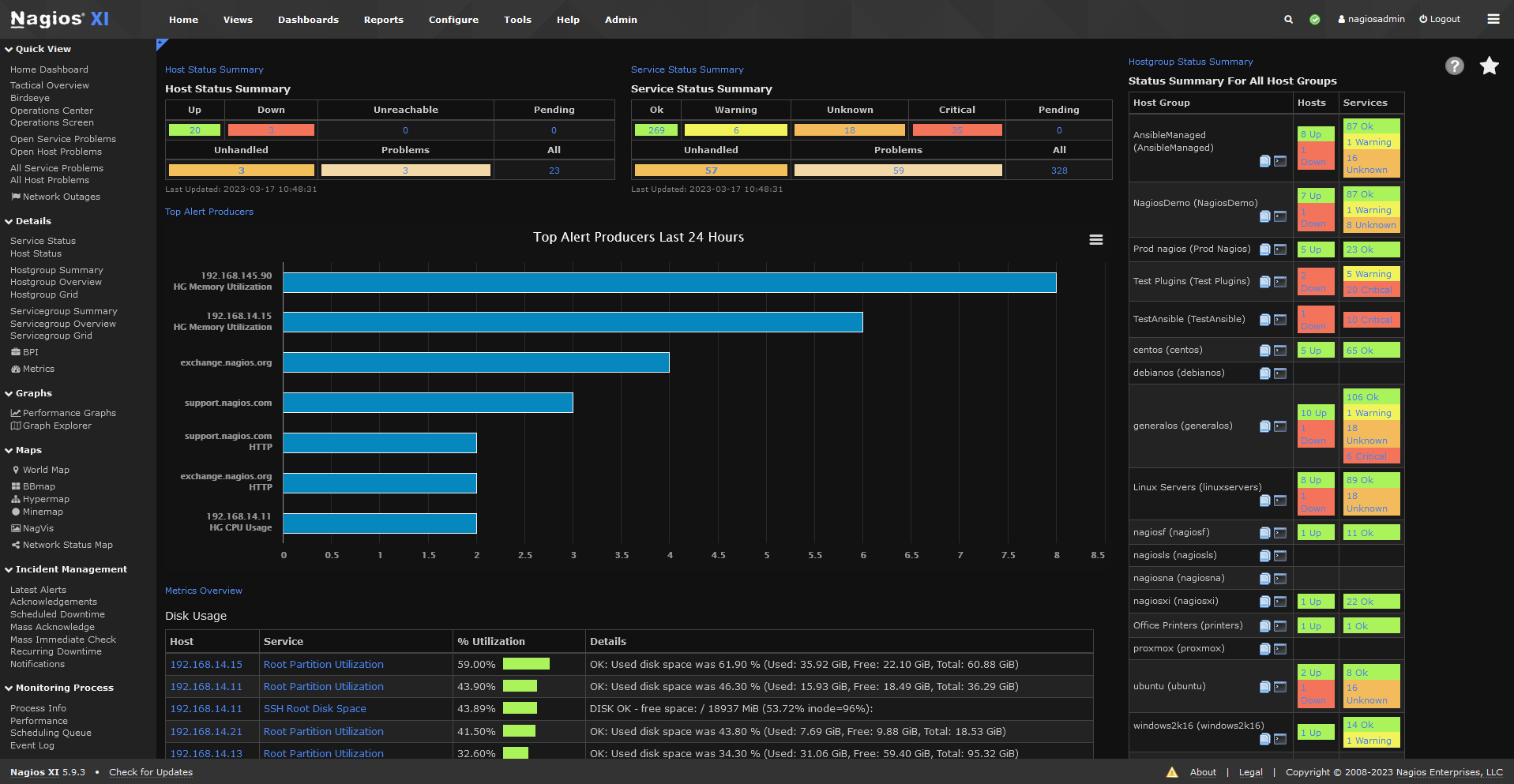
Nagios is one of the earliest and most full-featured open-source monitoring systems for Linux. It allows you to monitor infrastructures of all sizes by checking hosts and services via active agents. Nagios is highly customizable and compatible with a vast collection of third-party plugins for expanding its monitoring capabilities. Some key points about Nagios include:
- Agent-based monitoring via NRPE, SNMP, or passive checks
- Powerful event and alert handling with notifications via email, IRC, or nagios plugins
- Robust reporting and history through its web-based interface
- Check services like HTTP, SSH, SMTP and more via host checks
- Define complex hierarchies of hosts, contacts, contacts groups
While Nagios has a steep learning curve, it provides immense power and flexibility once configured. It works great for large or complex infrastructures in need of advanced plugin capabilities. Nagios is open-source and can be installed on most major Linux distributions.
Zabbix

Zabbix is another widely used open-source monitoring solution capable of tracking networked systems and services. Some key Zabbix features include:
- Agent-less and agent-based monitoring via SNMP, IPMI, JMX and other protocols
- Automatic discovery of network services, devices and new monitoring items
- Pre-built templates for common server components (disks, CPU, memory etc)
- Flexible triggers based on metrics thresholds with escalation actions
- Advanced visual Dashboard with graphs, maps and reports
- REST API and web interface for access from mobile devices
Zabbix offers robust scalability, high performance, and a user-friendly frontend. It is beginner-friendly compared to Nagios and has an active development community. Zabbix works great for medium to large networks with its built-in automation, templates and flexible triggers.
Icinga
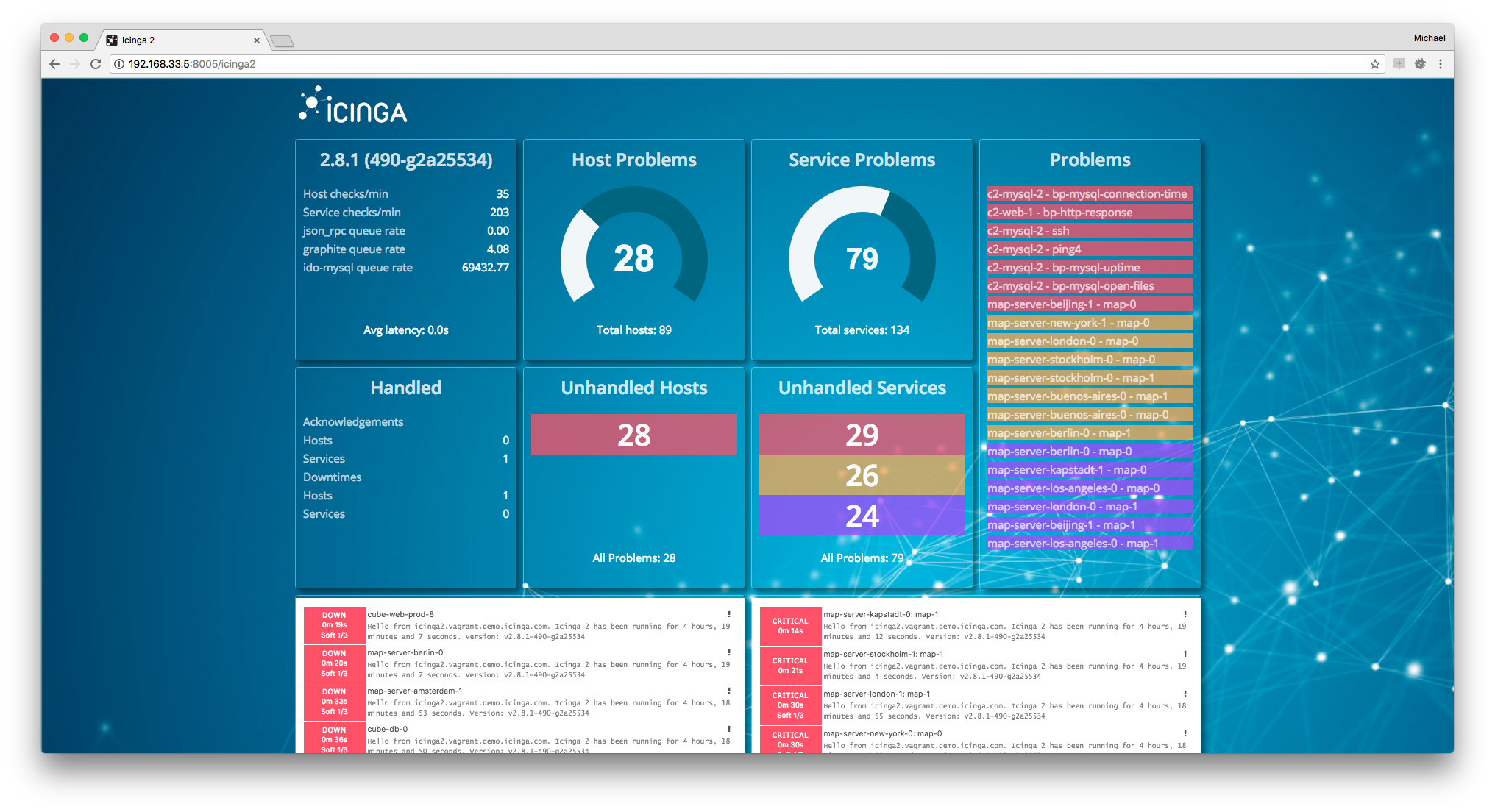
Icinga is a fork of Nagios focused on improving stability, scalability and the user experience. Some notable Icinga advantages include:
- More polished web interface and wizards for simplified configurations
- High availability capabilities through clustering for redundancy
- Improved performance on large infrastructures through optimized code
- Integration with PostgreSQL, MySQL, and Oracle for better database support
- Much better plug-in management and configuration inheritance
- Powerful business logic and notifications engine built-in
Icinga2 is actively developed and offers robust enterprise-grade features. It is suitable as a long-term, production-ready alternative to Nagios. Icinga’s streamlined interface also makes it easier for beginners to pick up compared to Nagios.
Cacti

Cacti is a popular open-source, web-based monitoring and graphing tool focused on system performance. Some top Cacti features include:
- Real-time and historical graphs of system metrics like CPU, disk IO, memory etc
- Data collection via command-line RRDtool and agent-based monitoring
- Flexible graph templating and report generation
- Integration with multiple databases and webhook notifications
- SNMP collection for network devices and appliances
- API and web interface for convenient mobile and remote access
Cacti excels for visual dashboarding of system and network performance. It works well for departments focused more on capacity planning than alerts/triggers. The intuitivegraphs make it easy to analyze usage trends over time.
Munin
![]()
Munin is a simple, lightweight monitoring tool primarily focused on system metrics collection and graphing. Some key Munin features include:
- Agent-based monitoring of servers via tiny Bash scripts
- Easy to deploy and runs on embedded devices or low-power systems
- Basic but clean-looking graphs of metrics like disk usage, memory etc.
- Built-in database and web server for centralized access
- Automatic graph updating and color-coding for analysis
- Simple to set up additional plugins as needed
Munin is best suited for small-to-medium deployments that prioritize low overhead. The simplified design trades advanced features for easy maintainability in Linux environments without complex requirements.
Monit

Monit is a useful open-source utility for monitoring Linux systems and services. Some primary Monit capabilities include:
- Checks system resources, processes, log files, directories and more
- Auto-remediation of detected failures through customizable actions
- Notification of administrators through email or SMS
- Detection of network problems through ping, port checks etc.
- Lightweight daemon that runs as a background service
- Easy installation and configuration through a single simple config file
Monit shines for basic server monitoring and automation without complex configurations. It is suitable for DevOps and small production environments with a limited number of services.
Ganglia

Ganglia is a popular open-source distributed monitoring system for high-performance computing clusters and grids. Key Ganglia features include:
- Collection of metrics from multiple clusters, grids and cloud infrastructures
- Embedded data storage and global metadata propagation between nodes
- Real-time global monitoring of cloud resources, grids and clusters
- Advanced data aggregation and multi-dimensional data rendering
- Seamless integration with visualization tools like Grafana
- High scalability for massive distributed environments
Ganglia is an excellent choice for monitoring large HPC stacks, data centers, and cloud deployments with its scalable multi-dimensional data collection.
Prometheus
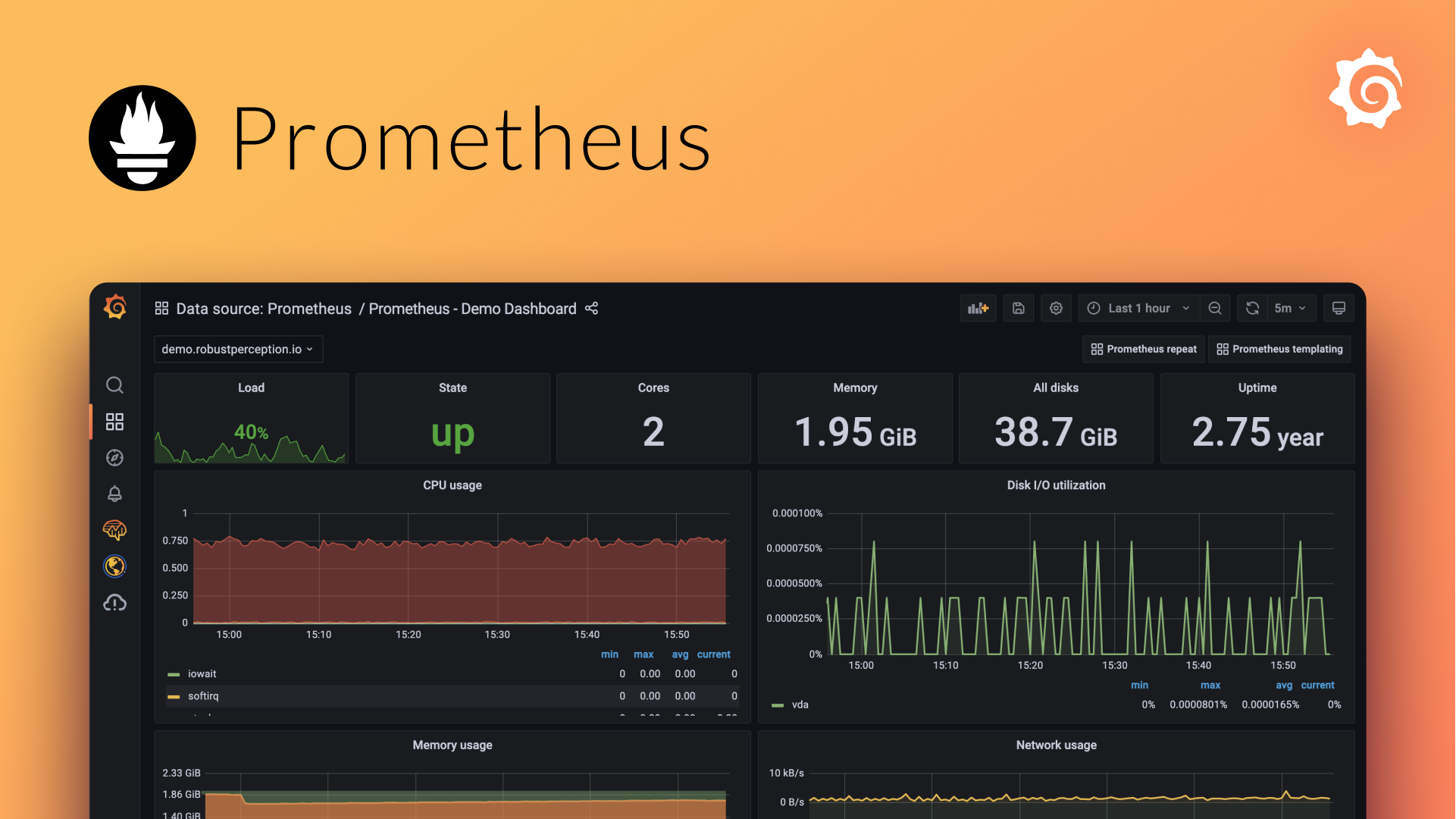
Prometheus is a popular open-source systems and service monitoring system from the Cloud Native Computing Foundation. Some key Prometheus features include:
- Time-series data collection with flexible multi-dimensional data models
- Powerful PromQL query language for analyzing metrics
- Agent-based and JMX-based monitoring of services
- Native support for container and Kubernetes environments
- Highly scalable with no single point of failure
- Extensible data collection via simple client libraries
Prometheus is exceptionally suitable for microservices and containerized infrastructure monitoring due to its scalability and Kubernetes integration. It also integrates well with frontends like Grafana.
Conclusion
In summary, Linux systems offer many powerful tools for monitoring server infrastructure, services, and metrics. In this article, we covered 8 top open-source and commercial options ranging from full-fledged enterprise solutions like Nagios and Zabbix to specialized tools like Cacti, Grafana, Prometheus and Monit. The right choice depends on factors like system size, requirements, skills, and budget. Many also integrate to offer a complete observability solution.
For simple environments, lightweight tools like Munin work well while Ganglia or Prometheus scale nicely for distributed or container infrastructure. Zabbix or Icinga strike a balance for medium use cases. Larger shops require full power of Nagios. And Grafana brings it all together visually. Proper system monitoring leads to major efficiency improvements through automation, early detection and preventative maintenance. It is key for optimizing uptime and performance.





